Building a simple recommendation engine in Neo4j
Let's build a simple recommendation engine with plain Cypher
Graph databases like Neo4j are an excellent tool for creating recommendation engines. They allow us to examine a large context of a data point potentially comprising various data sources. Their powerful storage model is very well suited for applications where we want to analyze the direct surrounding of a node. If you would like understand what makes graphs so powerful in comparison with relational models, read here.
In this article, I describe how we implemented a simple recommendation engine directly in Neo4j using only Cypher. The approach bases on basic NLP and simple conditional probabilities to find the most likely matching item. The implementation can be done in a handful of cypher lines in a single query. We run the query in real-time as the user interacts with the app. This simple approach yields very satisfying results and is a wonderful first version. It saves us a lot of hassle to provision and maintain additional external systems, which we needed for more complex approaches. Even though it works well, there are some limitations to this solution as well.
The domain: DayCaptain, tasks, events, areas and project
DayCaptain is a personal time planning app which allows users to create day plans consisting of tasks and events. The primary property of tasks and events is their title, which is a short string specifying it. One way to organize these objects is by assigning them to (life) areas and projects. An area is a larger and persistent theme, whereas a project is timely bound. Projects themselves can be assigned to an area, in which case they inherit the area. Instead of writing 'tasks and events' for the rest of this article, let's focus only on tasks for now.
Now, the goal is to detect the area assignment for a new task as the user starts typing in the frontend. For example: The user creates a task and starts to write "Deploy ETL pipeline" in DayCaptain. As he types, we want to detect the most likely area for the words the writes by analyzing other tasks comprising of these words.
Tokenization and stemming - the preparation
For the moment, we only consider the tile property of a task. In order to turn it into workable features, we need to extract its tokens and stem them. We use the StanfordNLP framework to process each input string as the user creates new tasks and events, and store their token usages as relations in the graph.
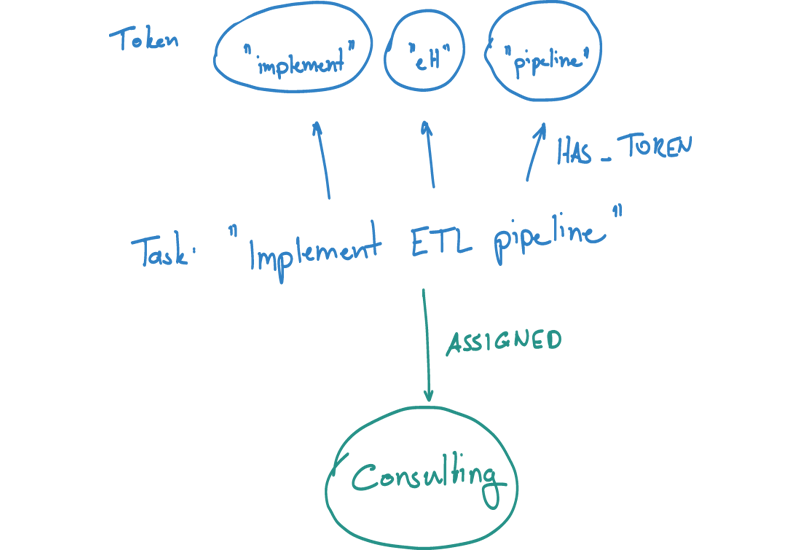
Sets, areas and conditional probabilities
Or objective is to find the most likely area assignment for a set of words which the user is currently typing.
Therefore, we want to find the area where the probability P(A|T) is largest.
In other words: Given a token T, we want to find the area A which has the largest probability of containing this word.
Let's start with a simple example.
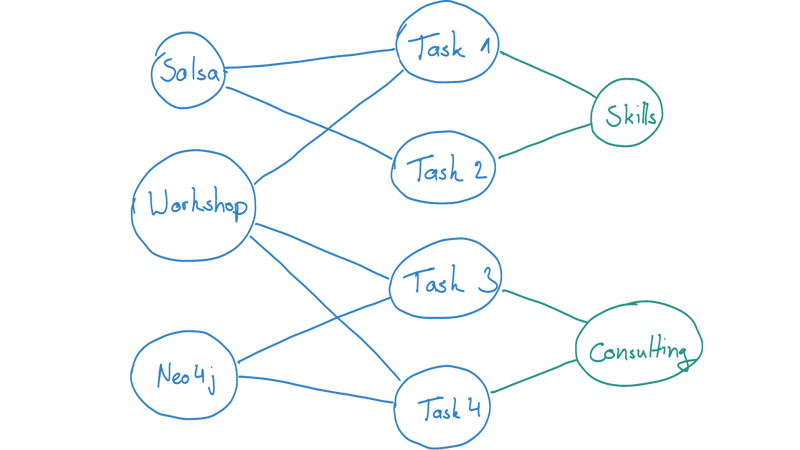
Now, as we can see, the tasks (or events) sit in between areas and token, and basically form the assignments of them. As we create new tasks and events consisting of tokens, and relating them with areas, we get more such indirect relations between areas and token. These indirect relations are exactly, what we want to analyze to find the recommendations.
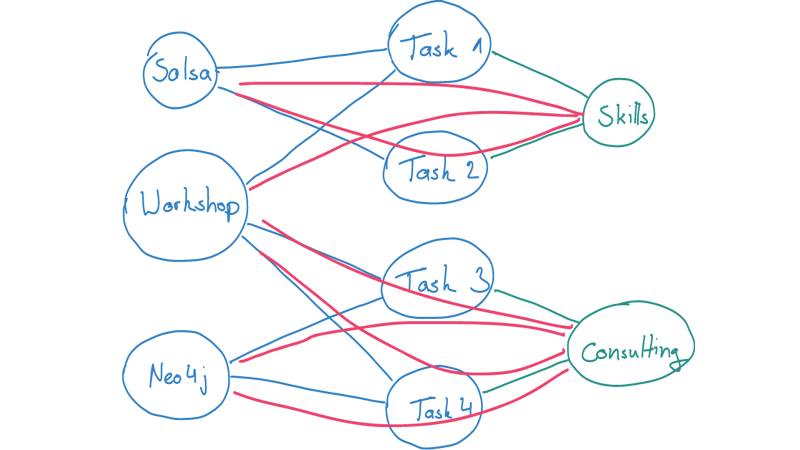
Now, form the picture above, we can also construct an assignment matrix between areas and token.
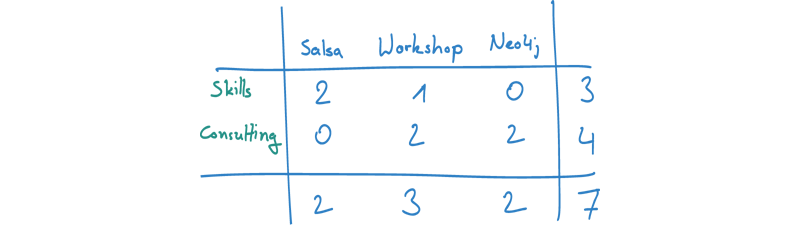
Having all these numbers at hand, we can easily calculate our conditional probability for P(A|T) = P(A & T) / P(T). Let's take the example of Token1 and Area2.
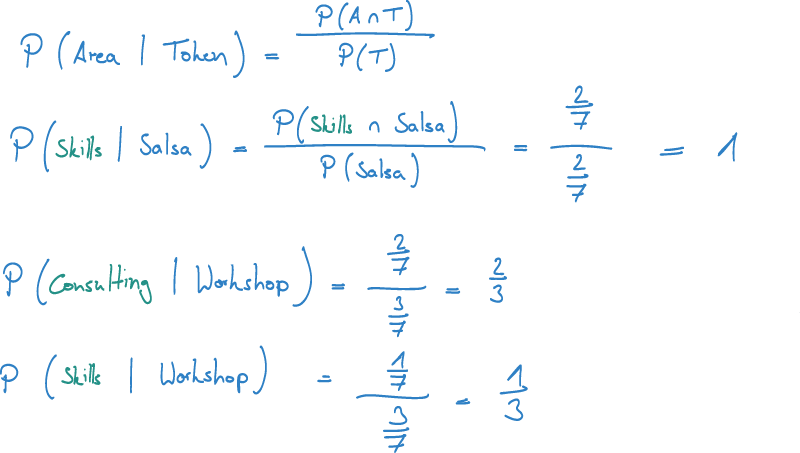
A very intuitive way to illustrate such probabilities is to view the as areas.
Our recommendation query is straight forward. However, this example is only works for a single token. The question is: How do we combine multiple words into such a probability calculation?
Finding recommendations for multiple words
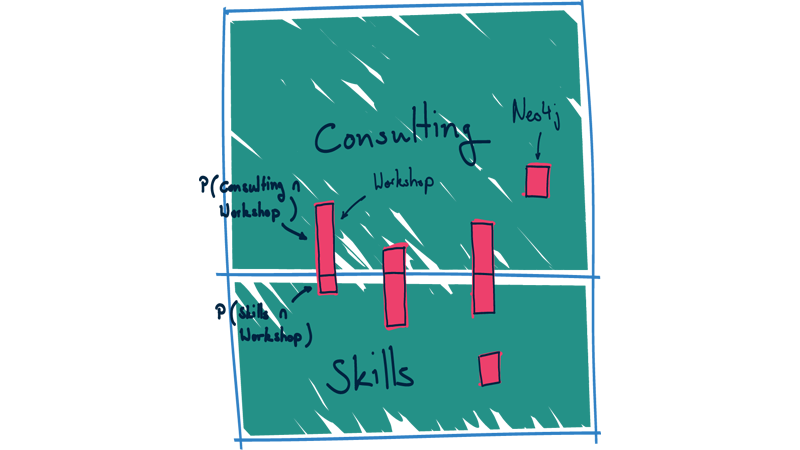
Each task and event can, and probably would consist of multiple tokens. To extend our model to such cases, the illustration as areas is particularly helpful.
Example: Let's say, we wanted to find the area assignment for the task "Prepare Neo4j workshop". Then, we want to find the probability P(A|"Neo4j" & "workshop"). From calculus, we can infer, that we need to find P(A & "Neo4j" & "workshop") and P("Neo4j" & "workshop"). If we view our area illustration (or our matrix) we can derive what these probabilities are. Here's the calculation:
As we can already see from the examples, we do not need the global count of assignments, because it always cancels out. Therefore, our recommendation query is as simple as fining the counts of assignments within each area. Here's the query:
MATCH (token:AnnotatedToken)<-[:HAS_TAG]-(i:Information)
WHERE token.lemma IN $tags
WITH count(i) as total_tf
MATCH (token:AnnotatedToken)<-[:HAS_TAG]-(i:Information)
WHERE token.lemma IN $tags
OPTIONAL MATCH (i)<-[:IS_ASSIGNED_TO*0..2]-()-[:IS_CONTAINED_IN*0..1]->()-[:RELATES_TO*0..1]->()-[:BELONGS_TO]->(area:Area)
WITH area, count(i) AS intersection, total_tf
RETURN area, intersection * 1.0 / total_tf AS p
ORDER BY p DESC;
Some notes to the query: In real DayCaptain, there are also modeled projects between areas and tasks.
The Information label is a superclass of tasks and events (or basically everything, which has a title property).
Also, the query is simplified in such a way, that it does not consider users.
In our production case, we actually limit this query to a specific user.
That's so simple - but how well does it work?
We have conducted a quantitative assessment of the recommendation engine and have even compared it to a deep neural network model on the same data. The results are more than satisfying. In both cases, we split our data set into a train and test set. Even though there is no training phase in our simple approach, we wanted to test whether the recommendation engine works well on data points it hasn't seen before.
We have a large body of data from myself, as I have been using DayCaptain for more than 4 years now. For both approaches, we measured how many times they predicted the correct result for a known task or event. Both approaches predicted the correct area in around 95% of the time.
Man, that's cool - but what does it mean?
Let's have a short discussion about this: Our simple statistic (or probabilistic) recommendation approach uses very simple maths, and a lot of intuition to produce very useful results. It is very easy and straight forward to implement in plain Cypher, and runs directly in our Neo4j backend. There's no overhead for adding external systems, there's are training cycles or models, which we need to manage, and there's low overhead in maintaining the code. We are actually able to query results in real-time (multiple times while the user is typing) without the need of any preparation of results. Compared to more sophisticated approaches like a deep NN model with a word2vec embedding, it yields equally good results.
However, the mayor downside of this approach is: It is limited to a simple feature set. Once we would like to consider more features in our recommendation, we had to model them explicitly into our query. It could become very complex and hard to understand, or even impossible to maintain. Not to speak of the complicated development process of finding the right way to combine multiple features into a reasonable result.
Let's round this one up.
Neo4j's powerful querying model allows us to build powerful recommendations right into the database. We created a very simple and very powerful prediction query to provide the best experience to our users. Our approach was really 80/20, and we reached some very good results. For us, the mayor advantage is the implementation directly in our graph database as it saves us from a lot of work for provisioning, training and monitoring additional systems. However, the application of such approaches is limited to a small set of features as the query may become rather complex and would require large effort to maintain and extend. The approach described here, definitely serves as a good starting point to build an initial working solution.
Let's team up - let me hear from you.
I hope you have enjoyed reading this article and that you could take away something out of it. If you have any questions or a different opinion, I warm-heartedly welcome you to leave a comment or contact me directly. Hit the subscribe button to read more like this. 🚀