What's the hype about graph databases? A technical interpretation
It's easy to come up with some answers by simply Googling the topic, however, as I found, most answers list benefits mostly superficially.
In today's never resting world new data is constantly created and is the fundamental asset of most businesses. Systems are available 24/7 and generate data every second of the day. Additionally, complex compositions of data generating and processing systems collaborate to provide services to the user. One question that I came across many times recently which - and which I've given careful thought as a result - is: What's the deal about graph databases and how are they different? It's easy to come up with some answers by simply Googling the topic, however, as I found, most answers list benefits mostly superficially. In this post I'd like to give a brief description about my understanding of their true value - independent of marketing slides from large companies and tech influencers.
Databases maintain and persist a materialized state of all previously processed events coming into our system.
An event is a self-contained and immutable message coming into our system. When we set up a database to process and store such events, we have to make various design decisions:
- What data would we like to store?
- How is it represented?
- At what layer of abstraction do we store data?
- Which events we would like to process and how to apply them to our data?
For example: We could store raw events as they come into our systems, or apply them as they come in to update our data.
A database has a purpose and reason for storing data in a particular way.
E.g. if the database serves as the persistence layer of a user-facing application to serve user requests in real-time, it should incorporate a representation that holds the data quickly accessible for that particular set of requests. For answering statistical business questions, in contrast, that take into account large amounts of historical data, this might not be the best approach.
Now, what's the difference between graph databases and relational databases? As graph databases gain more and more attention from many companies, and most companies also have traditional relational databases in place, I'd like to focus on these two here.
Relational databases are entity-first.
Let's start with the relational model. Relational databases store data in tables. A table represents an entity. I'd call them entity-first. The approach is to define a schema for a table and then store only objects of that particular type within that table. Therefore, similarly structured data is stored close together.
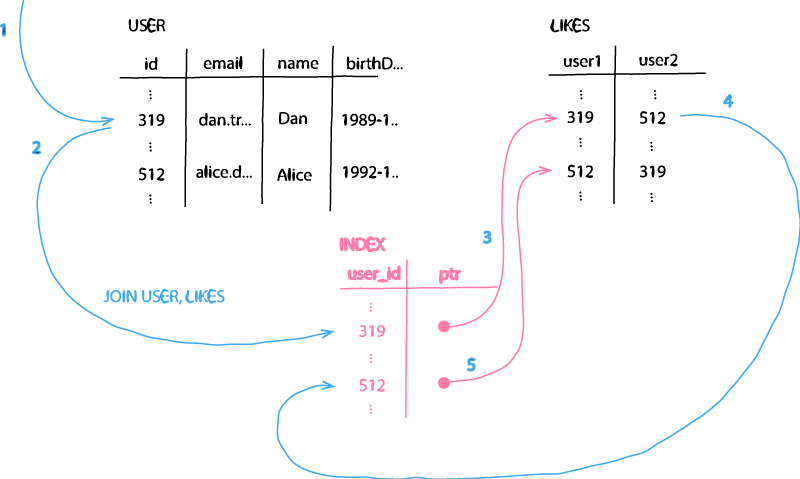
Relational models store relationships as data in the user domain.
There exists no concept of a relationship between data in a relational model. Meaning, you cannot define a relationship between tables. In order to link data in a relational model, you have to explicitly model the relationship into your data. You cannot distinguish between the actual data, and the data only kept to represent the relationship. The only way to model a relationship is to model it as a foreign key into your table - either as an attribute of your entity (one-to-one, many-to-one) or with an additional table (one-to-many, many-to-many). One could consider that mapping table as a relationship table and therefore the relationship as an entity. However, it doesn't come implicit from the technology to support relationships - rather we are creating new data. This leads to one fundamental implication: Relational databases store foreign keys as user data - i.a. references to another entry in an entity table. As the reference is data in the user domain the database cannot have an automatic mechanism to manage them - they are subject to user logic.
Graph databases are relationship-first.
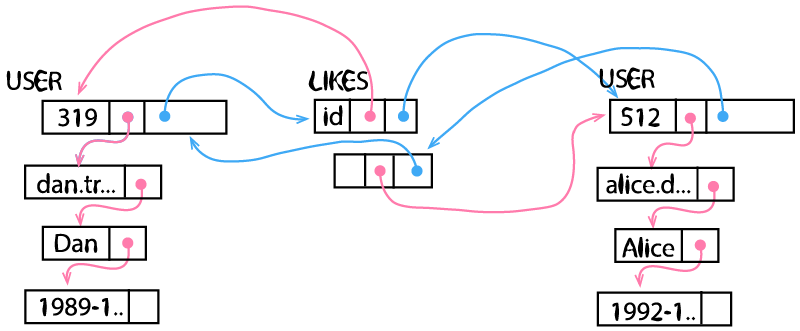
A graph model, in contrast, has an explicit concept for entities (nodes) and relationships (edges) - which makes it different. As we can define relationships between entities directly we do not need to care how to model them explicitly in our schema. We do not need to know about foreign keys and neither do we have to write logic about how to store them. We define a schema of entities and relationships and the system will take care of it. This has a huge benefit if we want to model highly connected data: The implementation can take care of references efficiently. Instead of storing additional data (the reference) in our data tables as attributes explicitly, the graph database system can store true memory pointers to the next related entity. Most graph database systems store data in a structure similar to linked lists. They store direct links to data which is connected, rather than similar objects. I'd say they are relationship-first.
The aforementioned differences in the two approaches lead to some implications about the use-cases each can serve well.
Graph databases store data like object-oriented languages.
As relational databases don't incorporate a concept of a relationship, we need to model them explicitly as data into our schema. This leads to a discrepancy from the object-oriented modeling that we use in most programming languages. Each object can maintain a collection of other objects it is related to. These references are usually pointers to objects in-memory, and we do not have to store them explicitly. Nor do we have to find the object in memory with some foreign key attribute. Therefore, quite some overhead is required to do the so-called object-relational mapping.
Graph databases store data like object-oriented languages - we have direct pointers to related objects. Therefore, the object-relational mapping is more straightforward.
The traversal of a single relationship can be done at constant time.
As graph databases can jump from one entity to a related one just by following a memory pointer, we call this index-free adjacency. We do not have to find a foreign key in a different table (using an index) or - even worse - find a key in a mapping table, and the resulting foreign key in a third table to follow a relationship. Therefore, the traversal of a single relationship can be done at constant time. Meaning, it is independent of the size of the data stored in the graph database. Whereas we have to scan one - potentially multiple - indices in a relational one, which is growing with the data size.
It just feels wrong to write multi-hop queries in SQL.
While it is indeed possible to model connected data and relationships in relational models, once we try to follow paths with multiple hops using SQL query language, we might get the feeling what we are writing down is not quite the thing that we want to accomplish. We have to join tables on some condition that we have to specify manually to find neighbouring data - potentially multiple times and therefore write ugly nested queries. It feels bulky and like a lot of overhead is occurring. If something like this happens, it's usually a strong indicator that we are using a technology not quite the way it was designed for. We don't want to join entire tables - we want to look up one particular data point.
In graph databases this looks different. As they were designed to query related data based on the structure of connection, they offer a concise and intuitive syntax to do so. We can specify exactly what paths we want to find. No join conditions or complex nested queries, no mapping tables - just the simplest description of what we want to find.
Conclusion
Graph and relational databases differ in one fundamental design principle: Graphs do have a concept of a relationship and relational don't. That's why a graph database can manage interconnected data much more efficiently. Still, both have their reasons for existence: Graphs perform better and are more intuitive to use when analyzing an entire context close to a single data point - potentially with multiple hops. However, if the exploration of highly joined and densely connected data is not a requirement, a relational model may serve the needs similarly well.