Understanding Apache Spark Hash-Shuffle
As described in Understanding Spark Shuffle there are currently three shuffle implementations in Spark. Each of these implements the interface ShuffleWriter. The goal of a shuffle writer is to take an iterator of records and write them to a partitioned file on disk - the so called map output file. The map output file is to be partitioned so that subsequent stages can fetch data merely for a specific partition.
Several approaches exist to accomplish this - each with specific pros and cons and therefore beneficial in different situations. The ShuffleManager attempts to select the most appropriate one based on your configuration and your application. In this post we will deep dive into the so called BypassMergeSortShuffleWriter, which is also referred to as hash-shuffle. We will understand how it works and elaborate on its up- and downsides to understand in which situations it might be a good choice to use.
How does the BypassMergeSortShuffleWriter work?
The hash-shuffle is based on a naive approach of partitioning the map output: it maintains a file for each partition. The name BypassMergeSortShuffle originates from the fact that its intermediate files do not need to be merged when creating the output file - therefore it bypasses the merge sort. As we shall see in later posts, the other implementations write multiple intermediate files each containing records from many partitions. These files need to be merged in the end to create a partitioned output file. The hash-shuffle in contrast, inserts the records of a partition only into a single file. Thus, no merging of files is needed. The writer opens a BufferedOutputStream for each file.
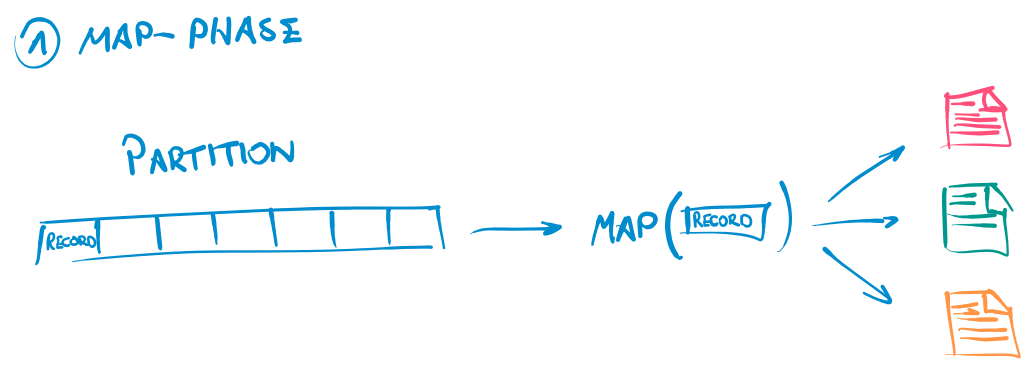
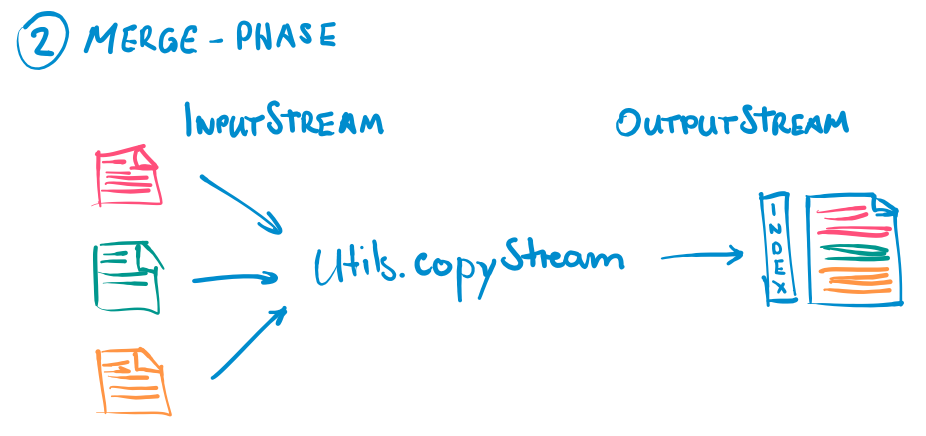
Once all records were written to the respective output stream, all the partition files are combined into one partitioned output file. This is done by reading each file using a FileInputStream and copying it using the Utils.copyStream method. This function copies all data from a FileInputStream to a FileOutputStream. Finally, an index file is created to enable readers to load data for a specific partition from the file.
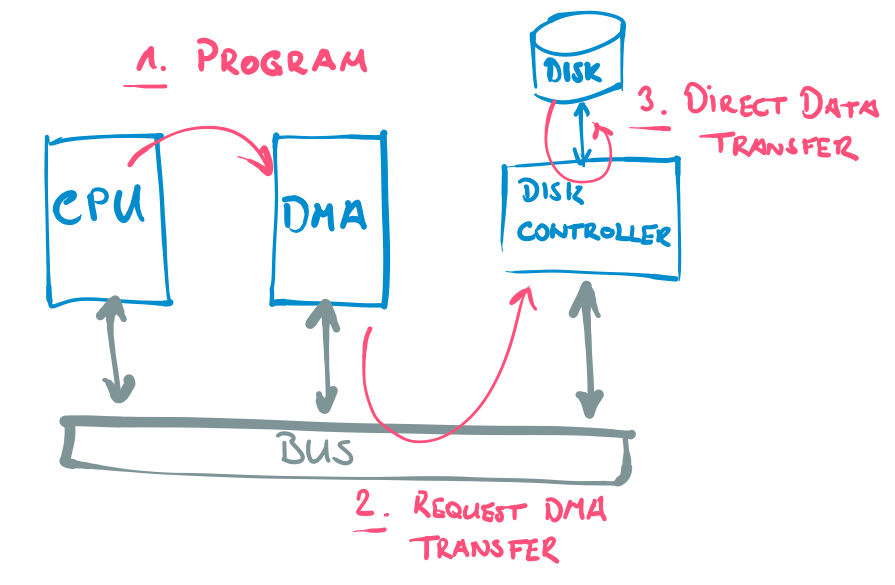
When looking at the hash-shuffle from a performance perspective it is valuable to know one implementation detail about it: The Utils.copyStream method implements two ways of copying a stream: either it uses the java.nio library, or it uses the FileOutputStream directly. The former approach utilizes the implementation of the java.nio.channels.FileChannel.transferTo method. This method copies bytes from the source location on the disk to the target location (eventually) without loading them into memory. Dependent on the actual implementation this may be achieved by using direct memory access (DMA). DMA offloads the work for loading and writing bytes from the CPU to a DMA controller which handles the transfer of bytes directly. In this case, the CPU only needs to initiate the transfer by programming the DMA controller. In the documentation of the transferTo method it says: "This method is potentially much more efficient than a simple loop [...]. Many operating systems can transfer bytes directly [...]". This emphasizes the fact that it is highly dependent on the implementation of the transferTo method - and therefore on the OS - whether it is more efficient or not.
If the transferTo is not used (default case) all bytes are loaded to memory from the input stream and are copied to the output stream. This approach certainly places much more work on the CPU and increases memory utilization.
What are the pros and cons?
The major drawback of the BypassMergeSortShuffle is that it consumes a large overhead of resources for each partition. It opens a file and maintains a BufferedOutputStream for every partition, each requiring a memory buffer of the size of spark.shuffle.file.buffer (default 32k). Resulting in R FileStreams and memory allocated for buffers of the size R * bufferSize - where R is the number of reduce tasks (equivalent to the number of partitions after the shuffle). Consequently, on an executor with C cores there exist C * R open BufferedOutputStreams at a time. Furthermore, after writing the R files, we must re-access and read them (eventually into memory) to create an integrated output file.
The major advantage (over other approaches) is the bypassing of the merge sort. As all intermediate files only contain records from a single partition, these files can be combined to form a partitioned output. Within each partition, however, the records are unordered.
What are the preconditions?
Considering these properties of the BypassShuffleMergeSort, it is beneficial to use only in certain situations: There is no point in opening a separate output file for each partition if a map-side combiner and aggregation is specified for the shuffle. In this case only one record would be written to each file. More importantly, it is reasonable to use the BypassMergeSort only for shuffling a small (whatever that means) number of partitions as we have a large overhead for each partition.
That brings us straight to the pre-conditions that need to be met in order for the hash-shuffle to be chosen by the ShuffleManager:
- No map-side combine & aggregation
- Small number of partitions: The number of output partitions of a shuffle is less or equal than the configuration parameter spark.shuffle.sort.bypassMergeThreshold.
What can we configure?
There are some configuration parameters that can be adjusted to influence the behavior of the hash-shuffle:
- spark.shuffle.sort.bypassMergeThreshold (default: 200): Only if the number of output partitions is smaller that the specified threshold, BypassMergeSortShuffleWriter will be used for the shuffle.
- spark.shuffle.file.buffer (default: 32k): This configuration specifies the memory buffer allocated by every output stream. A buffer of this size will be allocated for every partition.
- spark.file.transferTo (default: false): Whether the java.nio.channels.transferTo method should be used. This method - dependent on its implementation - enables to copy data between files using direct memory access (DMA).
Conclusion
The goal of a shuffle writer implementation is to create a partitioned map output file so that the subsequent stage can fetch relevant data. The BypassMergeSortShuffleWriter is one of three implementations and - as the name suggests - bypasses the merge sort that is performed by the alternative shuffle strategies. It is based on a very simple approach of opening a file for every output partition and commits records respectively. This approach certainly has its limitations and is beneficial to use merely in a limited set of use cases. The main drawback is that a buffer of a fixed size is allocated in memory for every output partition which makes it unfeasible to be used with many partitions. For a small number of partitions it might, however, be a good choice as it removes work for sorting records from the CPU and potentially even the final copying of files. Therefore, the BypassMergeSortShuffleWriter can be seen as highly specialized optimization for a very specific shuffle use case - in contrast to its actual origin of being an early and naive implementation.