Understanding Apache Spark Shuffle
This article is dedicated to one of the most fundamental processes in Spark - the shuffle. To understand what a shuffle actually is and when it occurs, we will firstly look at the Spark execution model from a higher level. Next, we will go on a journey inside the Spark core and explore how the core components work together to execute shuffles. Finally, we will elaborate on why shuffles are crucial for the performance of a Spark application.
Currently, there are three different implementations of shuffles in Spark, each with its own advantages and drawbacks. Therefore, there will be three follow-up articles, one on each of the shuffles. These articles will deep-dive into each of the implementations to elaborate on their principles and what performance implications they inherit.
In order to be able to fully understand this article you should have a basic understanding of the Spark execution model and the basic concepts: MapReduce, logical plan, physical plan, RDD, partitions, narrow dependency, wide dependency, stages, tasks, ShuffleMapStage and ResultStage.
Recap: What is a shuffle?
To understand when a shuffle occurs, we need to look at how Spark actually schedules workloads on a cluster: generally speaking, a shuffle occurs between every two stages. When the DAGScheduler generates the physical execution plan from our logical plan it pipelines together all RDDs into one stage that are connected by a narrow dependency. Consequently, it cuts the logical plan between all RDDs with wide dependencies. The final stage which produces the result is called the ResultStage. All other stages that are required for computing the ResultStage are called ShuffleMapStages.
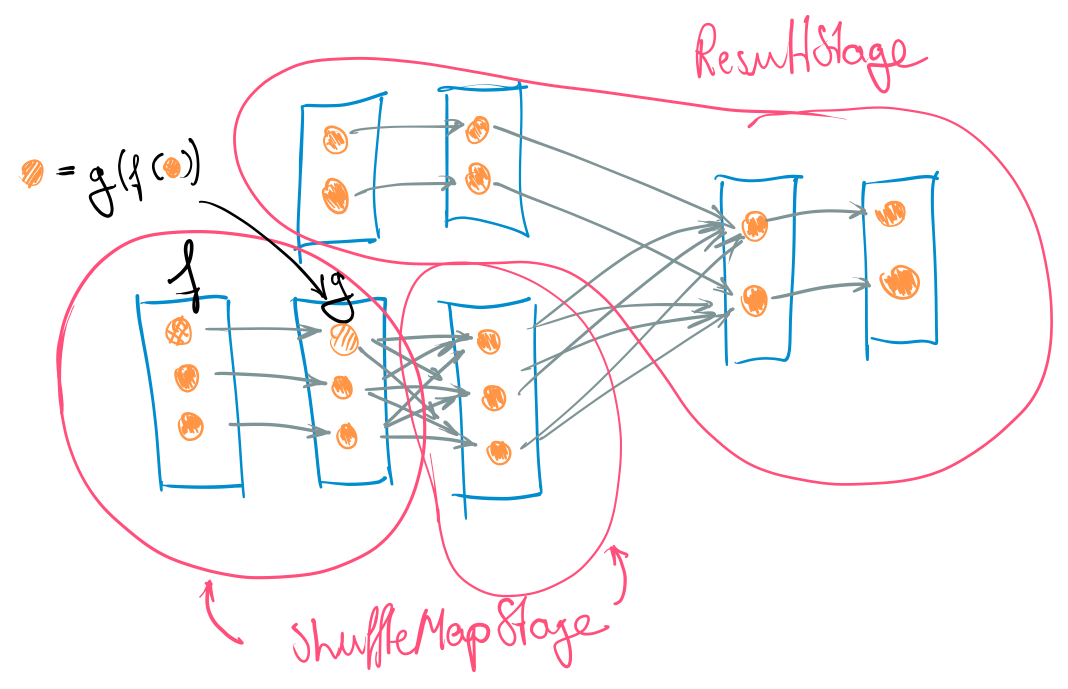
By the definition of a ShuffleMapStage (ending in a WideDependency) there must occur a redistribution of data before the subsequent stage can run. Hence, every stage has to end with a shuffle. Intuitively, we can think of the physical execution plan as a series of map steps (in the MapReduce paradigm) that exchange data according to some partitioning function.
What happens during a stage?
The physical plan that was generated by the DAGScheduler consists of stages, which in turn consist of tasks. The evaluation of a stage requires the evaluation of all partitions of the final RDD in that stage. Therefore, there will be one task for each of the partitions and, hence, the number of tasks of a stage is equal to the number of output partitions of the final RDD.
Once we start evaluating the physical plan, Spark scans backwards through the stages and recursively schedules missing stages which are required to calculate the final result. As every stage needs to provide data to subsequent ones, the result of a ShuffleMapStage is to create an output file. This output file is partitioned by the partitioning function and is used by downstream stages to fetch the required data. Therefore, the shuffle occurs as an implicit process which glues together the subsequent execution of tasks dependent stages.
When executing an action, the executors in our cluster do nothing different than executing tasks. This execution follows a general procedure for every task. Let's go through the execution of a single ShuffleMapTask on an executor:
- Fetch: Each executor will be scheduled a task by the TaskScheduler. The task contains information about which partition to evaluate. So the executor will access the map output files of previous stages (potentially on other workers) to fetch the outputs for the respective partition. The whole process of fetching the data, i.e. resolving the locations of the map output files, its partitioning, is encapsulated in each executors block store.
- Compute: The executor calculates the map output result for the partition by applying the pipelined functions subsequently. Note that this still holds true for plans generated by SparkSQL's WholeStageCodeGen because it simply produces one RDD (in the logical plan) consisting of one function for all merged functions during the optimization phase. Meaning that from an RDD point of view there is only one MappedRDD initially.
- Write: The ultimate goal of a task is to produce a partitioned file on disk and registers it with the BlockManager to provide it to subsequent stages. The output file needs to be partitioned in order to enable subsequent stages to fetch only the data required for their tasks. Generally, the output files are also sorted by key within each partition. This is required as the subsequent task will fetch the records and applies the function iteratively. Therefore, same keys should occur consecutively.
How is a task executed?
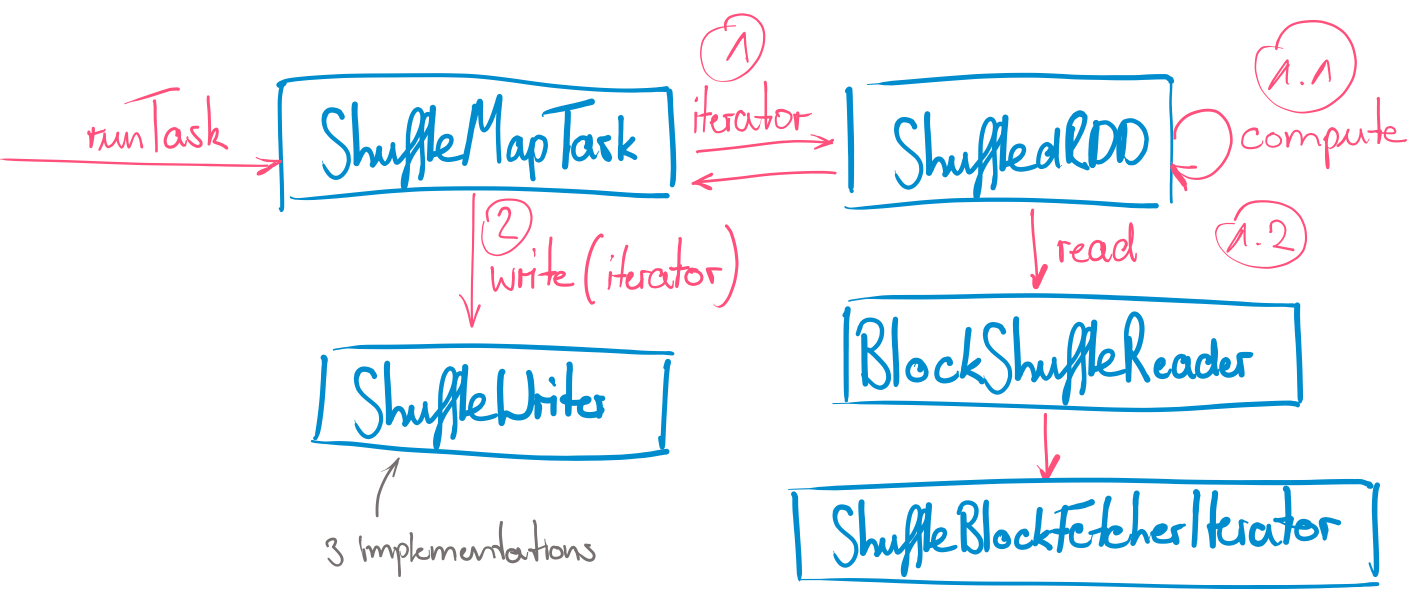
The diagram shows the principal execution of a ShuffleMapTask and the most important components involved. By looking at the flow of execution the structure of a general task described above becomes very apparent: Within the runTask method the partition of the final RDD is evaluated by using its iterator over the records. This iterator internally uses the RDD's compute method which specifies how to compute the partition. For a ShuffledRDD for example, it accesses the BlockShuffleReader to read the required data. The BlockShuffleReader in turn encapsulates the distributedness of the records of the partition and is responsible for accessing local and remote block stores to provide the requested records. The BlockShuffleReader uses the ShuffleBlockFetcherIterator which iteratively fetches blocks form the BlockManagers while obeying memory and count limits. The resulting iterator is directly passed to the ShuffleWriter.
The ShuffleWriter is the component we are going to look at in detail throughout this series of blog posts. Currently, there are three implementations of a shuffle writer each with its own upsides and drawbacks. Which one will be selected is mostly dependent on what kind of operation we want to execute and the configuration. The selection of the respective strategy is done within the only implementation of the ShuffleManager at the moment: the SortShuffleManager.
Shuffles and performance
If we look at the execution of tasks from this perspective and realize that nothing else happens on executors than the three fundamental steps described above, it becomes obvious to see that these are the only three places where performance bottlenecks can occur. We also understand that basically all of these steps happen simultaneously on each executor and stress all of our resources:
- CPU: Used for evaluation of functions, serialization, compression, encryption, read/write operations.
- Memory: Used by buffers for fetch and write, heap for execution, heap used for cache.
- Network: Used while reading data from other workers, providing data to other workers.
- Disk: Writing intermediate results to disk, loading previous map output files that are red by other workers.
However, it has been found that the main bottleneck in modern clusters is the CPU. This is because many tasks are CPU-bound and disks and networks in today's clusters provide decent throughput. Therefore, large efforts have been put into 'bringing Spark closer to bare metal' through project tungsten. One of the efforts made resulted in a shuffle strategy (an implementation of ShuffleWriter) called 'tungsten-sort'. Meaning, that performance and resource consumption of shuffles in general could differ significantly, dependent on what shuffle implementation is used.