The bigger picture: How SparkSQL relates to Spark core (RDD API)
Apache Spark's high-level API SparkSQL offers a concise and very expressive API to execute structured queries on distributed data. Even though it builds on top of the Spark core API it's often not clear how the two are related. In this post I will try to draw the bigger picture and illustrate how these things are related.
The most fundamental concept that the Spark core is based on is the MapReduce. MapReduce is a mixture of declarative and procedural approaches. On the one hand it requires the user to specify two functions - namely, map and reduce - to be executed concurrently on distributed data. This is the declarative part - we only tell MR what to do, not every step of how to accomplish it. On the other hand, the logic within the two functions is of procedural nature. Meaning that we write code which is executed step-by-step on each piece of data. The logic itself - the semantics of the function - is opaque to the framework. The only thing it knows about it are the input and output types of these functions. Thus, automatic optimization is merely possible on the level of map and reduce functions.
As elaborated in my talk at Spark & AI Summit Europe 2018, Spark core basically adds a new layer of abstraction on top of the MapReduce paradigm. It does nothing different than specifying higher-level transformations which are translated into an optimized chain of map and reduce functions. Optimizations, however, only can happen on the level of map/reduce functions. Consequently, Spark core's optimization strategy is limited to pipeline narrow transformations into stages (watch this for a deeper understanding of Spark core).
SparkSQL in contrast provides a way to specify entirely declarative queries on distributed data. In order to do so, however, the structure of the data needs to be known to the framework by providing an explicit schema (i.e. structured data). The API then allows the user to specify queries on the data providing many predefined operators (very similar to SQL). A structured query is therefore a combination of operators - also known as expression. The API provides two ways to specify user queries: using functions defined in Dataset-API, or by writing SQL queries directly. Both ways simply provide a way to tell Spark how the resulting Dataset can derived from the input Dataset, using predefined operators. In some cases, however, if no suitable operator exists in Spark, we see ourselves urged to write so called user-defined functions. These functions are simply a way to execute procedural code on each record.
The query (or expression) that the user specified to produce the desired result builds up an abstract syntax tree (AST). The tree is composed of expressions and operators, which take expressions themselves. In contrast to Spark core where we assemble a chain of opaque functions being executed, we now have a chain of logical operands that we use to produce the final result. As we can distinguish these operators we can now apply optimization rules on the level of these operations. The Spark optimizer, called catalyst, specifies many generally applicable rules of optimizing such trees.
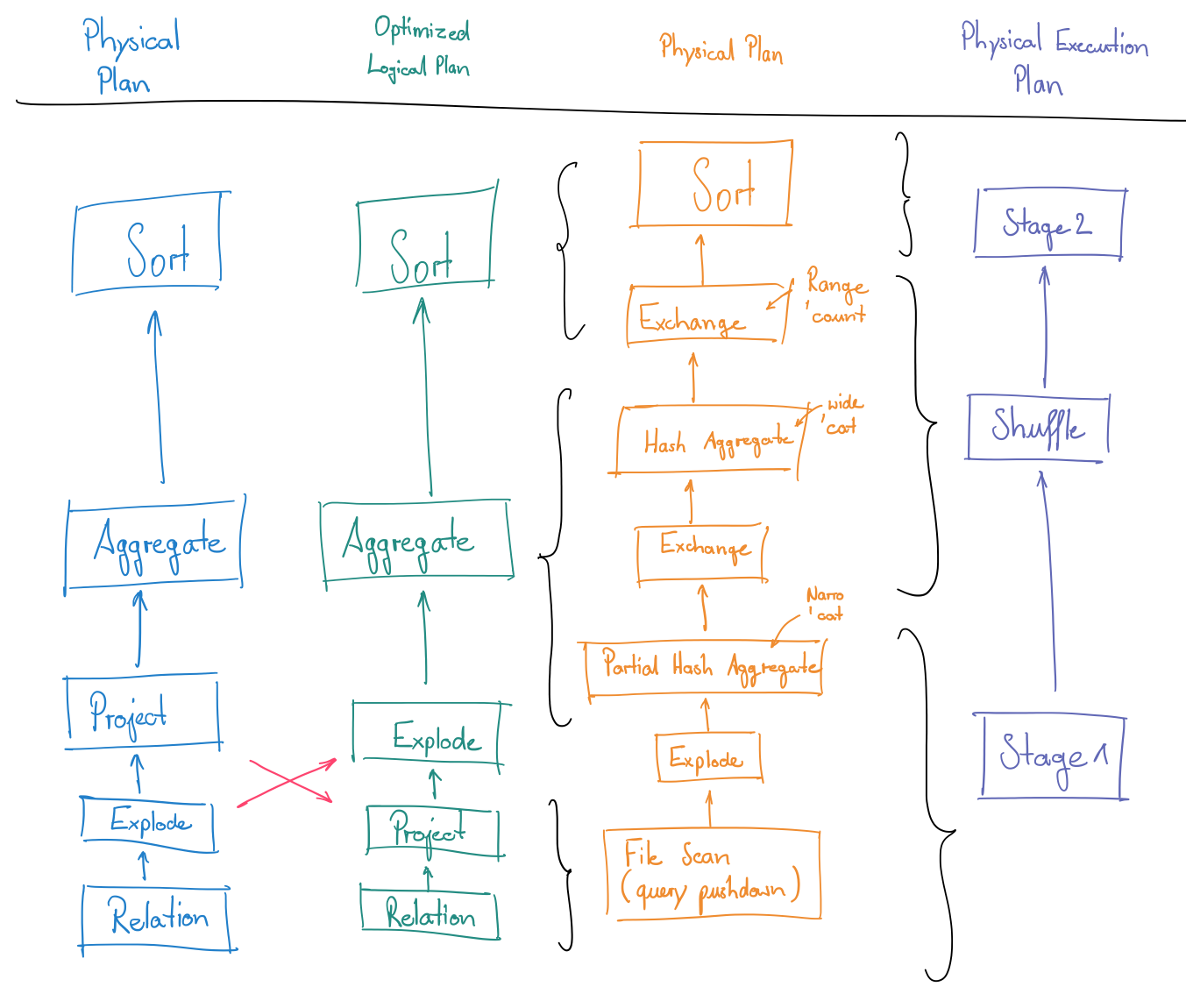
In the first step it transforms an AST into another AST by resolving column and table names using an internally maintained catalog. The resolved logical plan is then transformed into an optimized logical plan by recursively applying optimization rules until a fixed point is reached. Many optimization rules are implemented by the catalyst. However, the catalyst is designed to be easily extendable with custom rules. Note that optimization on an operator level becomes inherently possible as we use logical operators provided by the framework to specify our queries in a declarative way. We could also write user-defined functions for all of the functionality available by SparkSQL. However, we would end up with exactly the same degree of optimization as if we used Spark core: namely, an optimization on stage-level, as stage-internals are opaque to the catalyst.
Now, the interesting question is: how do we bridge the gap between an AST, representing our query, and the Spark core, which SparkSQL "is build up upon"? There is another major step in the query execution process: physical planning. This step transforms a logical plan into a physical plan by replacing logical operators with physical ones. It does so by applying two sets of optimizations: rule-based and cost-based.
The rule-based optimization, similarly to the logical optimization, applies a set of rules to transform a subtree into a logically equivalent one. Even though the result stays the same, the rule influences the way the result is produced (e.g. pipelining, predicate pushdown). This step is similar to the transformation step that transforms a logical plan into a physical plan in the Spark core, which pipelines together narrow dependencies into stages. The cost-based optimization, in contrast, replaces operators that have various execution strategies, like joins. Each of the execution strategies may have different implications for the performance. The cost model is utilized to make assumptions about the most efficient strategy.
Finally, each expression of the optimized AST is transformed into an AST of scala code that evaluates the expression. At runtime, this code is compiled to Java bytecode, which will be shipped to the executors. Pipelining operators and compiling them into a single function reduces the overhead of having to parse the expression AST every single time it needs to be evaluated and reduces virtual function calls. Parsing and compilation refactor these steps to an only-once task. The generated functions basically implement an iterator that applies the expression to each entry of a partition.
After the code was generated for pipelined expressions, we build up a logical plan of RDDs. We end up with one RDD for each generated code function and an RDD for every join selected by physical planning. Spark core transforms this logical plan into a physical execution plan consisting of stages and tasks. The physical plan can be executed by the cluster simply by scheduling tasks to the executors.
We have seen that the benefits of using higher-level APIs like SparkSQL originate from the fact that we write declarative queries using operators provided by Spark. Spark understands the semantics of a query and can optimize on a operator-level by replacing patterns in the query with more efficient ones. Consequently, if we write user-defined functions to express our logic, we prohibit the catalyst form logically optimizing our query, as the code written within the function is opaque to the optimizer. The optimized query is transformed into a physical plan of map/reduce (map/shuffle in Spark terminology) steps during physical planning (by pipelining), which directly relates to the Spark core execution model. The functions executed by each stage are compiled at runtime into Java bytecode and sent to the executors. This reduces overhead for parsing the expression tree again for every record.