Choosing the right data model
One essential choice to make when building data-driven applications is the technology of the underlying data persistence layer. As the database landscape becomes more and more densely populated, it is essential to understand the fundamental concepts and their implications to choose the appropriate technology for a specific use-case. A very comprehensive overview on a conceptual level can be found in Martin Kleppmann's big data bible "Designing Data-Intensive Applications". Kleppmann writes: "... every data model embodies assumptions about how it is going to be used. Some kinds of usage are easy and some are not supported; some operations are fast and some perform badly; some data transformations feel natural and some are awkward." He compares currently existing data models by considering various criteria. Here, I will use these criteria to provide an overview of existing concepts and to elaborate on their advantages and shortcomings.
The properties I find most useful to distinguish different data models and to compare them against each other are the following:
- Schema flexibility: Whether a schema is required and when it is enforced. Two major categories exist: schema-on-write and schema-on-read. The former one ensures that only data compatible to the schema can end up in the data store. The latter one allows data of all format in the database and offloads compatibility issues entirely to the consuming process.
- Data storage locality: Whether related data is stored closely located (nested data) or in multiple places (various tables). Referencing data can be achieved using foreign keys (meta data stored along the referenced data) or pointers using addresses (non-exposed meta data managed by the database).
- Join support: Whether a database system supports the resolution of references using joins.
- Impedance mismatch: The degree of divergence between the application model and the database model (e.g. object-oriented vs. relational model). The larger the impedance mismatch the higher the effort required from the translation layer (e.g. object-relational mapping).
- Update granularity: The smallest granularity level of updates. The larger the granularity, the more overhead occurs for fine-grained updates (e.g. updating one field in a document requires to re-write the entire document).
These are sufficient to describe and outweigh advantages and disadvantages of currently existing data models for storing and retrieving data.
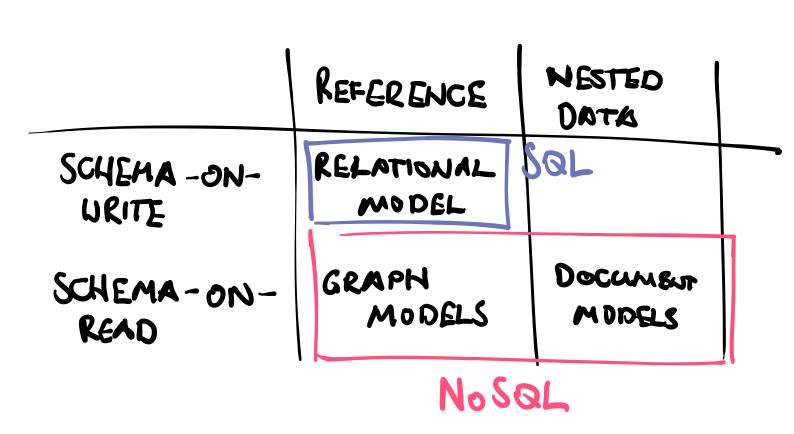
On a higher level, data models are commonly distinguished by the schema flexibility. Two major groups evolved, which are basically separated by this property: SQL and NoSQL. The relational data model (SQL) enforces the schema on write. Meaning that data that is inserted into a table necessarily needs to match a static schema. Otherwise the insert fails. This is similar to compile-time type checking as it fails early before the execution. NoSQL models on the other hand support so called dynamic schemata, also referred to as schema-on-read. This means that any kind of data can be inserted into the database without the need to match a schema. Rather the reading process is assumed to handle whatever data is read from the data store. This adds flexibility to the schema of an application as there is no need for migration routines and forward/backward compatibility are much easier to accomplish. This property is especially valuable in times of quick iteration cycles of development teams and zero-downtime deployment requirements.
The second level distinction is along the data locality axis and further divides the NoSQL technologies into two sets: document models and graph models. Document models store related data close to each other in documents. Related data is nested within documents rather than using references to other entities (foreign keys) like in relational databases. The data model does not consist of entities and relationships but rather of documents with nested entities. This makes it easy to model one-to-many relationships without joins. However, many-to-one relationships are complex to realize as data would either be duplicated in all documents or needed to be referenced. Joins, however, are in general not supported by document models so that the application layer would need to implement the logic of resolving many-to-many and many-to-one relationships. Document databases have the advantage of being very close to the object-oriented model by supporting nested objects. This reduces the impedance mismatch and therefore the complexity in the translation layer.
A third group are graph databases which provide schema flexibility but in contrast to document models place emphasis on the relations of entities rather then keeping them nested. Graph models like relational models consist of nodes (entities) and edges (relationships). They do not store related data close to each other but provide directly traversable pointers. The data is kept in various places on disk, though, unless in relational models, it is not required to perform joins on ids to resolve relationships. This makes it especially performant to perform recursive queries by simply traversing edges (pointers) of the desired type. Therefore, graph models are very well suited for highly interconnected data with lots of many-to-many relationships. Graph models require indices on properties to enable direct access to nodes.
The boarders between these categories blur as one adopts concepts from another, trying to compensate shortcomings of particular use-cases. Several implementations of SQL for example provide a keyword for performing recursive joins. However, what can easily be done in graph models requires large effort in relational models even if there exists a convenient way of writing it down. Moreover, it is generally possible to model one data model as representation of another. However, this naturally results in generally overly complex and awkward side effects and certainly vanishes performance advantages of the implementing technology.
It is valuable to know the underlying concepts of various efforts to store and retrieve data. From these concepts arise implications for the performance of certain operations we might perform on the database system. Having understood these concepts enables us to validate our choice of the data model against our expected access patterns. It might occur the situation, however, where we need to outweigh contradicting use-cases that cannot be served by one single technology. In this case it may be reasonable to choose a database implementation that makes efforts to compensate for the weaknesses of it's own approach. As requirements change and that particular use-case becomes more important for the application it is crucial to keep in mind the divergence of use-case and model.