What is Stream Processing?
Stream Processing vs. Batch Processing
Coming from various projects in the big data landscape of German companies I realize that many of the companies are facing similar problems. They have old legacy systems in place that are very good at what they were designed and built for at that time. Today, new technologies arise and new things become possible. People are talking about stream processing and real-time data processing. Everyone wants to adopt new technologies to invest in the future. Even though I personally think this is a reasonable thought, I am also convinced that one has to understand these technologies first and how they were intended to be used. As I was working with various clients I realized that it's not too easy to define in a clear way what stream processing is and what use-cases are that we can leverage it for. Therefore, in this series of articles I will share some thoughts of mine and we will elaborate these two approaches to understand better what they are. In this first article I will try to give a clear distinction between the well-known batch processing and stream processing.
The relational database model is probably the most mature and adopted form of database. I guess that almost all companies have it in place as a central component to implement their operational business. Usually a copy of this central data store exists to be used for analytical use cases. The replication and the analytics queries, however, usually run as so called batch jobs. Even though most of us might have an extensive background in relational databases, I would like to start the article with a clear definition of the characteristics of a batch job.
What is Batch Processing?
A batch job usually executes as follows:
- Read all input data,
- execute transformations / logic,
- write result to a sink.
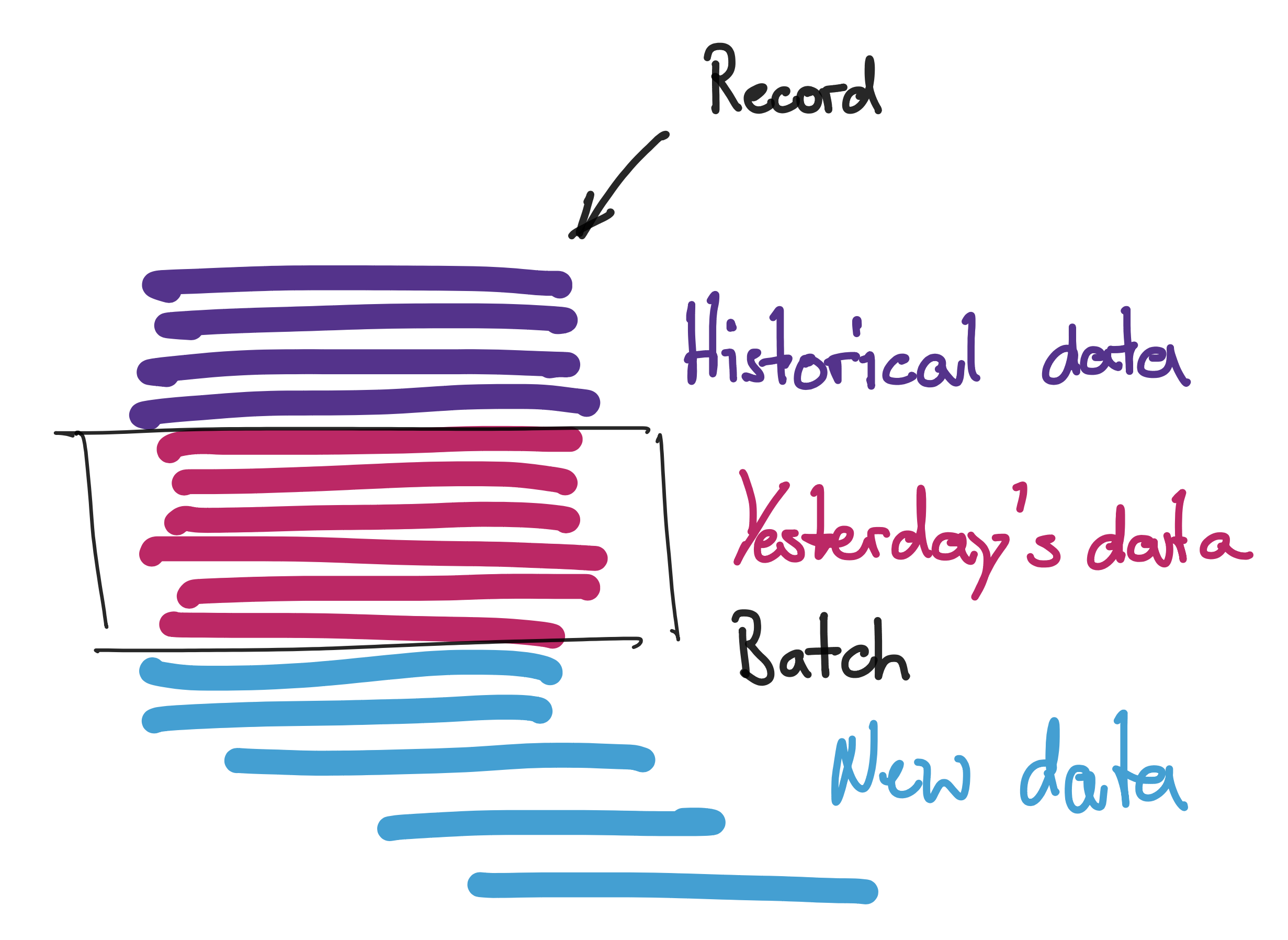
The key part is that we read the entire input that we want to process with our query in first, before we start processing. Therefore, we are viewing our data "after-the-fact". Meaning, that all data that we want to look at needs to be there already. However, as we are dealing with operational data, this data is ever-changing. We are analyzing data that is generated by our core business case and therefore it will continue to be change until we drop out of our business. Therefore, to be able to perform a batch job (and view data after-the-fact), at some point in time, we must take a snapshot of the underlying data and run our logic on "what is there yet". This artificially divides our ever-changing dataset into batches of a particular size. Usually the batch size is specified by some time interval that we want to process new events (e.g. once a day, twice a day, once an hour).
What are the Limitations of Batch Processing?
Naturally, this artificial division of our input data set into batches of a fixed time interval leads to a limited currency of our processing result. This limited currency of our result data set in turn limits the insights and use-cases that we are able to build on top of it. For example if we process our data only once a day, we have the results of yesterday's business day available only today.
What is Stream Processing?
In order to overcome this shortcoming of batch processing we could go ahead and reduce batch sizes until we have results available with the period we desire for our particular use case. We could process them once an hour, once a minute or once a second. If we keep on reducing the batch interval we will eventually process every event as it comes in immediately. However, this would involve decent overhead to query the database for new events every couple of milliseconds. Furthermore, the value of a single record query are even more limited than results that are available only once a day. As batch queries are designed to read all records before they start processing, there is not too much insight which we can draw from a single-record batch.
Imagine we wanted to sort our dataset by some particular key. If we look at a batch of one day's data the result we get will be just as expected: an ordered list of events of that day. However, there is no point in sorting a single-record dataset and therefore our query is actually worthless. Therefore, there exists a different approach to process events as they come in. This is usually referred to stream processing.
Stream processing is a special processing pattern for a special type of input data which differs from batch processing in various ways. The fundamental characteristics of stream processing are:
- Handle unbound dataset: We work on a dataset that receives updates continuously. There will always be new records as long as we are in the business.
- Process records immediately: We want to handle every record as it is added to the dataset. We want to process it with low latency (whatever that might mean in numbers).
- A record is always an event: Every data record in the stream is an event.
An event is a
- small,
- self-contained,
- immutable object
- that describes that something happened
- at some point in time.
In essence, stream processing is the handling of an ever-growing dataset consisting of events which are immutable records. As events cannot be changed the only way to update the dataset is to create new records. Therefore we are dealing with an append-only dataset and want to process every event as it arrives.
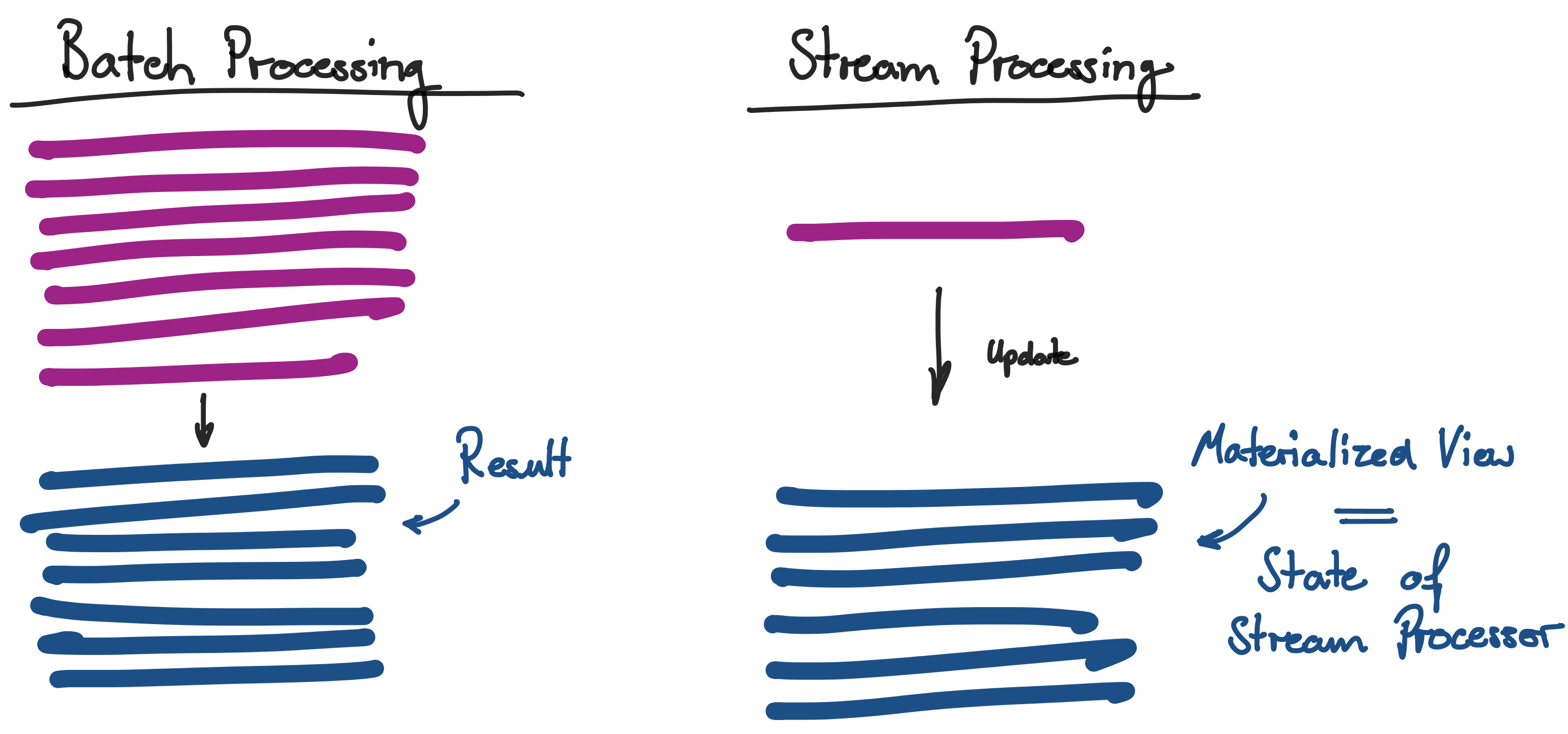
Let's see how we use stream processing to perform the previous example of ordering the dataset by some number. Generally, whenever we need a global view on the data withing a stream, the stream processor needs to maintain a state. In our example this state is a so called materialized view. This materialized view is updated with every new event as it comes in. Like this, we essentially update our result with every new event as it arrives. The current state for each point in time can be reproduced by replaying the entire stream from the beginning and applying the same logic to the events.
Conclusion
Even though the term stream processing is in everyone's mouth and it seems it can be applied to every use case, we have seen that it is more a special processing pattern for datasets with special characteristics. Stream processing means to handle an unbound and ever-growing dataset by processing every record as it comes in. This dataset consists of events which are small, self-contained and immutable objects that describe that something happened at some point in time. The crucial property of a stream is that all records are immutable and therefore we are dealing with an append-only dataset. Whenever we process such an event stream we need to maintain a state across events to have a global view on the data. To process a newly arrived incoming event we simply apply it with our logic to the current state. As long as we keep the history of our event stream we will always be able to reproduce this state from any point back in time. Whenever our use case does not meet any of these requirements it is most likely not very suitable for being implemented as streaming application.
In the next article we will elaborate on the connection between event streams and the concept of a table in a relational database.